
Index Fundamentals of Relational Database
Knowledge of database systems is essential to software engineers, and it’s unfortunate that I don’t have much exposure to databases (especially relational ones) at work. Luckily, there’s this highly rated database course from CMU with quite a lot of learning materials, which provides me with a good chance to catch up on this area.
My current plan is to go over indexing and transactions first and this particular post will be grouping some index related notes. The major reason behind this this is that I have recently just gain some high-level understanding of these 2 topics by reading Designing Data-Intensive Applications book, and going over them in more details again could facilitate my understanding of them.
This post will go over the followings:
- structure of B+ tree
- comparison between B tree and B+ tree
- insert/delete operations on B+ tree
- more B+ tree index concepts (composite index, clustered index, covering index, partial index)
- concurrency control on B+ tree index
Images in this post are borrowed from course materials of the course linked above.
Structure of B+ Tree

In B+ tree, each node fits into a fixed-size page. There are generally 2 types of B+ tree nodes: inner (or intra) nodes, and leaf nodes.
Inner nodes consist of key boundaries and identifiers of their children’s pages (i.e. record id, or “pointers” to their children). Typically a node in modern RDBMS will have several hundreds of pointers to their children, and if the boundaries and pointers of a node can’t fill up a entire page, that page will have some blank, ununsed space. Inner nodes of B+ tree need to be at least half-full (e.g. in a tree with branching factor n, a node needs to have at least n/2 keys) to maintain the balancing feature of B+ tree, which means if a node is less than half full, there will be some re-balancing operations. This operation, along with the case where a insertion causes a node to be overfull, will be discussed in “operations on B+ tree” section.
On the other hand, a leaf nodes stores both the keys and the corresponding “values”. Double quote here is added because different databases may have different implementations of the “values” (we’ll get to this in “more specific B+ tree index types” section), but in general they will provide information for us to find the value in a tuple. It’s worth pointing out that the sibling pointers were not included in the original concepts of B+ tree, but was introduced by a variation of B+ tree called B-link tree. These pointers are added so that range queries can directly move to the sibling pages when neede, instead of going back to the parent level and then down to leaf nodes again, which is more efficient.
Comparison Between B+ Tree and B Tree
The major difference between a B+ tree and B tree lies in inner nodes. A B tree stores both the keys and the corresponding values for boundaries in an inner node, where B+ tree only store keys. The major benefit brought by only storing keys in inner node is that, since each page on disk has fixed size, more boundaries can be fit into a single page when values are not stored, and this essentially increase the tree’s branching factor and decrease the tree’s height. Since searching in a balanced tree is of O(height), a shorter tree can speed up the search. There are of course some downsides: by storing the values only in leaf nodes, any read/write in B+ tree would need to go all the way down to the leaf level. Also, when a key is deleted from B+ tree, the key used in inner nodes (if any) is not guaranteed to be removed, which means we store some unnecessary data.
Insertion and Deletion in B+ Tree
Reading a key in B+ tree is relatively straightforward (N-ary search), which doesn’t involve much complexity because the structure of a tree remains unchanged. On the other hand, insertion and deletion of a key might entail re-structuring of the tree to maintain balanced property (i.e. every node needs to be at least half-full, as mentioned in ealier section). We are particularly interested in figuring out what happens then a node gets overfull or less than half full. Example operations will be performed on a B+ tree with branching factor of 3, and the images below comes from this helpful web visualization tool.
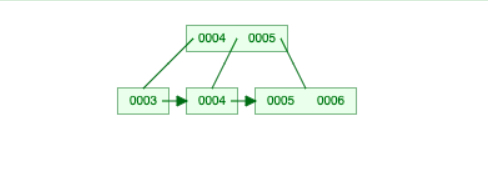
Let’s first take a look at an insertion case below. When we insert key 7 into the tree on the left, it first follows the path “greater than or equal to 5” and fit itself into the bottom right node. Then since the bottom right node gets overfull, it splits from the middle into a node holding key 5 and another node holding keys 6 and 7, and merge its middle key 6 into its parent node. Then its parent node gets overfull too and undergoes the same process. By doing this recursive split operations, the tree is now re-balanced.
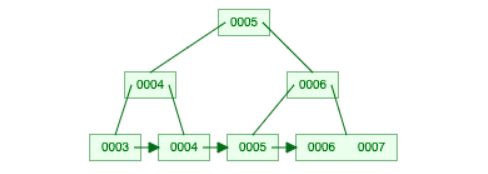
Deletion is a bit more complex than insertion because it has two possible types of cases. Let’s now make some deletions on top of the insertion outcome above. First consider deleting key 5, which makes the leaf node holding 5 to be empty (less than half capacity 1). B+ tree will first look at if some keys can be borrowed from its sibling node, and in this case it finds that key 6 can be borrowed from the bottom right node because its sibling can remain more than half full after taking a key off, so it borrows 6, and updates its parent node.
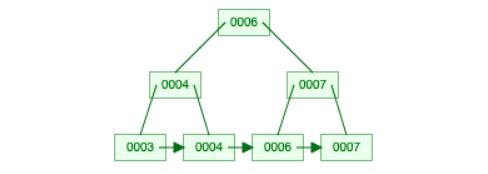
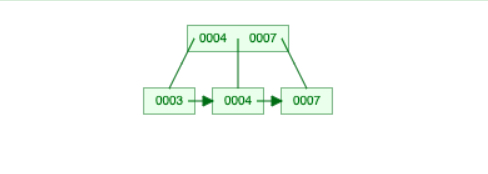
The other senario is illustrated by further deleting 6, where the target node can’t borrow keys from its sibling. When the node holding 6 is removed, its parent (the one that holds key 7) will be less than half full, and needs to be merged with the node holding 4 at the same level.
More B+ Tree Index Concepts
Clustered Index
We mentioned in previous section that the value stored in leaf nodes can differ across database implementations. There are generally two types of implementations: directly storing the row data, or storing a “record ID” (i.e. a page ID or something else that identifies where to read the row on disk). The first type of index implementation is called clustered index, and the second type falls into secondary index. The advantage of using clustered index is that it saves disk I/O operations, since we can retrieve the valued needed directly.
In MySQL with InnoDB, when we create a table, it first check if there’s a primary key specified, and makes clustered index out of it (the index will be named PRIMARY). If we don’t specify a primary key, it checks if there are any columns marked as unique and non-null, and chooses the first such column to build clustered index (the index name will be the chosen column name). If this type of columns is not found either, it generates clustered index (named GEN_CLUST_INDEX) using the row ID. The leaf record in MySQL secondary index will be the primary key column for the row, along with the columns that are used to create the secondary index. So if the database searches for a key using the secondary index, it needs to first go down the secondary index tree to retrieve the primary key, and use that to then go down the clustered index to retrieve the actual data value. We can inspect the indexes created for a table using
SHOW INDEX FROM <table_name> FROM <db_name>
Selection Condition on Composite Index
An index can be created using multiple columns. Some DBMS can use B+ tree for indexing if any of these attributes is provided. MySQL doesn’t support this, but is able to use any leftmost prefix of the composite index. The “leftmost” prefix is defined as the longest prefix before hitting a range query. For example, if we have an index on (col1, col2, col3), and we have a query statement like
SELECT * FROM Table WHERE col1=val1, col2=val2, col3 BETWEEN val3_1, val3_2
then MySQL will use the B+ tree to find all nodes that has col1=val1 and col2=val2, and then use a linear scan to find the nodes where col3 satisfies the BETWEEN condition.
Covering Index
In some cases, all the columns we want to retrieve with a query are included in the index columns. This type of index is called covering index. When the multi-column index is not a clustered index, we typically need to follow the steps discussed in “Clustered Index” section: get the primary key from our multi-column index, and search again in the clustered index to get the row. With covering index, since all the attributes needed are in the composite, non-clustered index, it can return directly and saves us an extra search in the clustered index.
Multi-Threaded Index Concurrency Control
Latches
Before diving into concurrency control on index access, we need to be clear about the definition of “latch” (i.e. to distinguish it from “lock”).
| Locks | Latches | |
|---|---|---|
| Separate | Transactions | Threads |
| Protect | Database content (rows) | In-memory data structures (buffer pool, indexes) |
| During | Entire transaction | Critical section |
| Modes | Shared, exclusive, update, intention | Read, write |
| Deadlock | Detection & resolution | Avoidance |
Reader-Writer Latch and Latch Crabbing
Reader-writer latch can be implemented on top of spinlock, and allows concurrent readers. Other concurrent access forms (read and write, write and write) will block until the latch is release by earlier operation. It’s worth pointing out that reader-writer latch maintains read/write queues to avoid starvation. For example, if threads 1 and 2 first read the data with read lock, and thread 3 wants to write to the same piece of data, it needs to wait and will be put into the write queue; then when thread 4 wants to read the same data, since thread 3 is already in the write queue and is waiting for the lock, thread 4 needs to wait and be put into the read queue, instead of sharing read lock with thread 1 and 2.

Latch crabbing aims to allow multiple threads to access/modify the B+ tree at the same time. Its basic idea is to get the latches of a parent node and a child node, and then decide whether to release the latch of parent node depending on whether it’s “safe” to do so. We consider releasing the parent node latch as “safe” when we are sure that insert/delete on its children (and grandchildren and so on) will not require a split/merge on parent node (i.e. parent node is more than half-full for deletion, or is less than full for insertion). The example below illustrate the case for deletion.
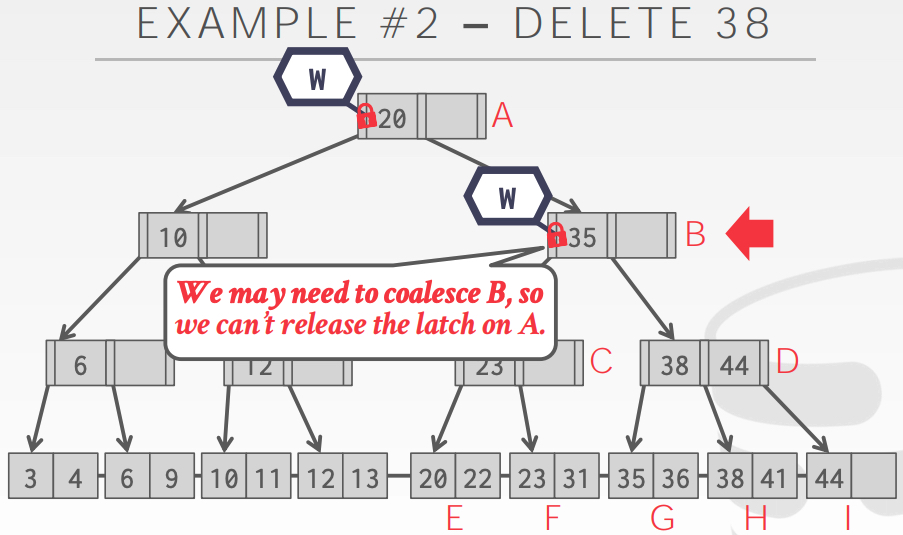
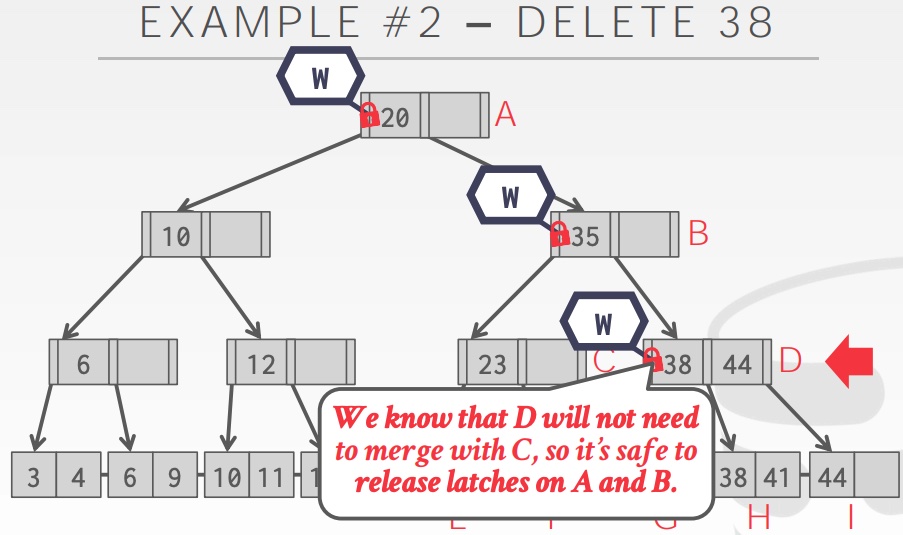
Optimistic Latching Algorithm
The problem with latch crabbing idea described above is contention, especially with nodes on upper level (an extreme example would be the root node of B+ tree). Thus, optimistic latching algorithm is proposed. When an update operation is started, we assume that accessing the target leaf node for update is safe, and take read latch on all nodes above the leaf node. If we end up finding this optimistic assumption is not true, we abort the previous operation, and try again with write latches all the way down.
Summary
In this post we’ve briefly reviewed many key concepts regarding RDBMS indexes, which is probably the first step to build up my knowledge system on relational databases. In future posts I plan to first go over the major concepts and techniques for transactions, and then try to actually use a DBMS (most likely MySQL) at work and note down some pratice experience. So stay tuned!